
Databases are some of the most complex pieces of software conceived since the advent of the computing age over half a century ago1. Nearly every piece of technology ends up touching the database in some way shape or form. Despite the ubiquity of Databases in the software stack, the vast majority of developers have been conditioned to treat databases as more or less a black box -- complex dense pieces of software conjured up by arch wizards and mavens ensconced in the rarified elite tiers of database companies or places like Google. The adage for the rest of us as it goes is never attempt to write your own database.
That said, despite their longevity, we have seen continued innovation in the space that first started with Hadoop arriving on the scene about 2 decades ago. The ClickBench website now lists over 50+ databases in its benchmark suite2 . And that's just the analytics engines. With the recent trends of rewriting everything big data in Rust3 not a month goes by without an interesting new project trending in the Hacker News. In this post we will take a look at how easy (or hard) it is to build Databases using Apache Datafusion and whether you can in fact, as a mere mortal realistically build a custom database and innovate around the developer experience.
Most modern databases can be disaggregated into compute and storage layers, with sophisticated query engines responsible for the "compute" portion of the database. A query engine typically consists of a Query Parser, Logical Plan generation and then the Physical Plan generation to run the computations on the Execution Engine. A query generally goes through multiple optimization phases in the logical plan generation as well as physical plan generation. No matter what the target use-case of the end system is, the query engine more or less follows this model.
Given decades of database research that has gone into each of these individual layers, the bar for writing a functional query engine with table stakes features remains strikingly high. And you need to nail all that before you can get around to writing your use-case specific features. While there are many projects that help you write some of these layers individually, Apache DataFusion remains the only game in town that helps you with the entire gamut.
You can think of DataFusion extensible database development toolkit. At its most basic level, you can use it as a query engine a la DuckDB with its builtin SQL and Dataframe front ends, while at the same time you can extend or even wholesale replace different layers to build your own experience entirely.
In the rest of this post we will walk through how to extend DataFusion to add your own operators to its execution engine and then weave it through the Physical and Logical planners and expose it to the frontend.
Building a top DataFusion#
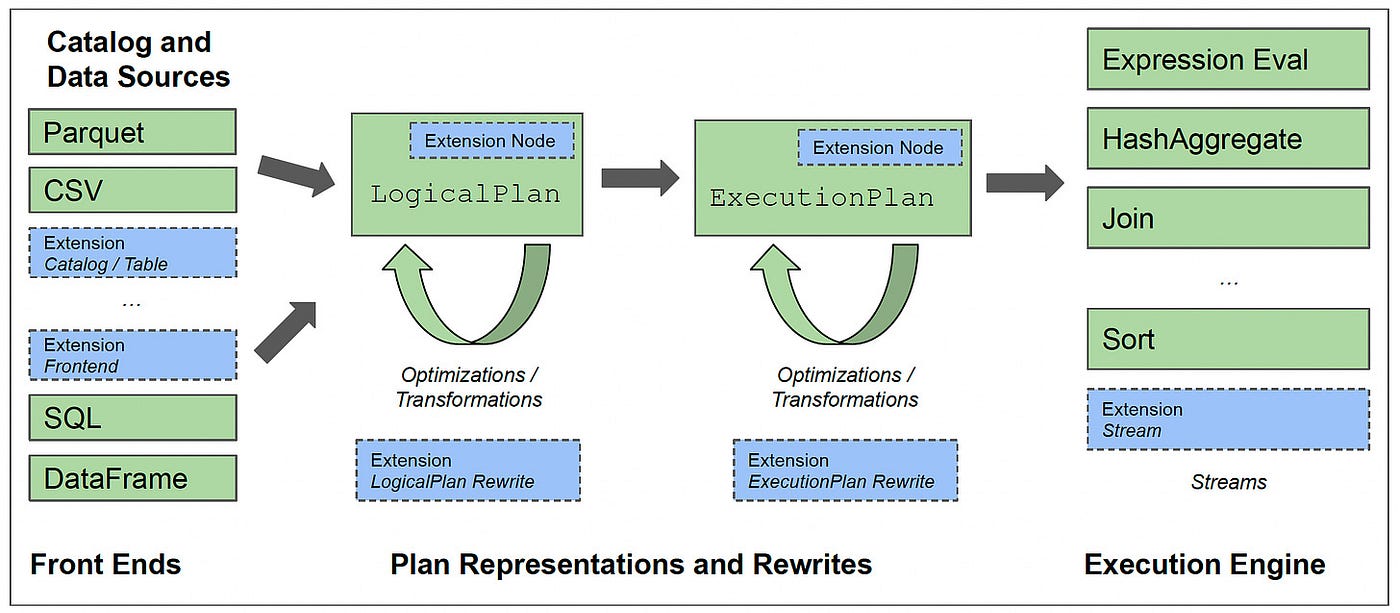
DataFusion architecture
At Denormalized, we are building a duck db like single node experience for stream processing applications. While DataFusion does have some support for unbounded computations, it doesn't have a streaming window operator. Windows are at the core of stream processing applications, they provide an easy way to bucket infinite data streams into finite buckets so that we can apply aggregations over them.
For this tutorial we will implement a simple window operator for infinite streams. Our operator will have the following signature --
pub fn window(
self
group_expr: Vec<Expr>,
aggr_expr: Vec<Expr>,
window_length: Duration,
slide: Option<Duration>,
) -> Result<Self> { ... }
Writing the Execution Plan#
An ExecutionPlan represents a node in the DataFusion Physical plan. This is where the actual code with our custom computations would go. DataFusions execution model is pull based, meaning that the execution starts at the sinks and works its way up the physical plan. Calling the execute method on this trait produces an asynchronous SendableRecordBatchStream of record batches by incrementally deriving a partition of the output by running computations over Execution Plan's input.
In our use case, ExecutionPlan's execute() method returns a struct GroupedWindowAggStream which implements a RecordBatchStream, a wrapper around futures::Stream trait. The actual computations should be implemented within the poll_next() of the Stream implementation.
impl RecordBatchStream for GroupedWindowAggStream {
fn schema(&self) -> SchemaRef {
self.schema.clone()
}
}
impl Stream for GroupedWindowAggStream {
type Item = Result<RecordBatch>;
fn poll_next(mut self: Pin<&mut Self>, cx: &mut Context<'_>) ->
Poll<Option<Self::Item>> {
let poll = self.poll_next_inner(cx); // Code to compute the record batch goes
here.
...
}
Here in our example, calling the poll_next_inner for a streaming window takes care of
- Processing the incoming data.
- Accumulating rows into open windows.
- Updating the watermark (which is behind a mutex)
- Opening new windows if required.
- Closing any triggering windows and producing the output RecordBatches from them.
Hooking into the Physical Planner#
Having created our custom Execution Plan, we need to make the Physical Planner aware of its existence. Implementing the ExtensionPlanner for our ExtensionPlan is all we need to do here.
Extending the Logical Plan#
Now that we have the custom Execution Plan implemented along with ExtensionPlanner, we need to add a companion node to the Logical Plan. This not only allows us to expose this to the SQL/DataFrame frontends but also hook into the logical optimizers for optimizations such as the predicate pushdowns.
In DataFusion we need to first implement a user defined Logical Plan Node and then add a LogicalPlanExtension to the logical plan builder which exposes this to SQL/DataFrame frontends.
Logical Plan to Physical Plan#
The last piece of the puzzle is the touch point where the logical plan gets converted into the physical plan. For this, we will implement a custom QueryPlanner that ensures that the physical planner is initialized with the custom extensions we wrote for our ExecutionPlan.
Custom Optimization Rules#
Since our operator implemented a group by aggregation, we need to ensure that all the rows for a particular group end up in the same partition. To that end we will add a new physical optimization rule to add a HashPartition operator on our group keys.
Putting it all together#
Finally, all we need to do is construct a DataFusion session with the custom QueryPlanner we wrote above as well as the additional physical optimizer rule we added and voila, now we have our own extended version of DataFusion.
let state = SessionStateBuilder::new()
.with_default_features()
.with_config(config)
.with_query_planner(Arc::new(StreamingQueryPlanner {}))
.with_optimizer_rules(get_default_optimizer_rules())
.with_physical_optimizer_rule(
Arc::new(EnsureHashPartititionOnGroupByForStreamingAggregates::new(),)
)
.build();